How Engineering Teams Win in the Age of Agents
Agents made execution cheap. The bottleneck moved to context and verification. Here's the operating model engineering teams are using to win.
Most engineering teams are running the wrong race.
They have adopted AI tools, added them to existing sprint workflows, and measured success by whether developers feel more productive. Some do. Delivery speed has not materially changed for most of them.
The problem is not the tools. The problem is that the process underneath has not changed, because most teams have not understood what agents actually changed. Agents made execution cheap. That shifted the bottleneck. The teams winning right now rebuilt their process around where the bottleneck actually is.
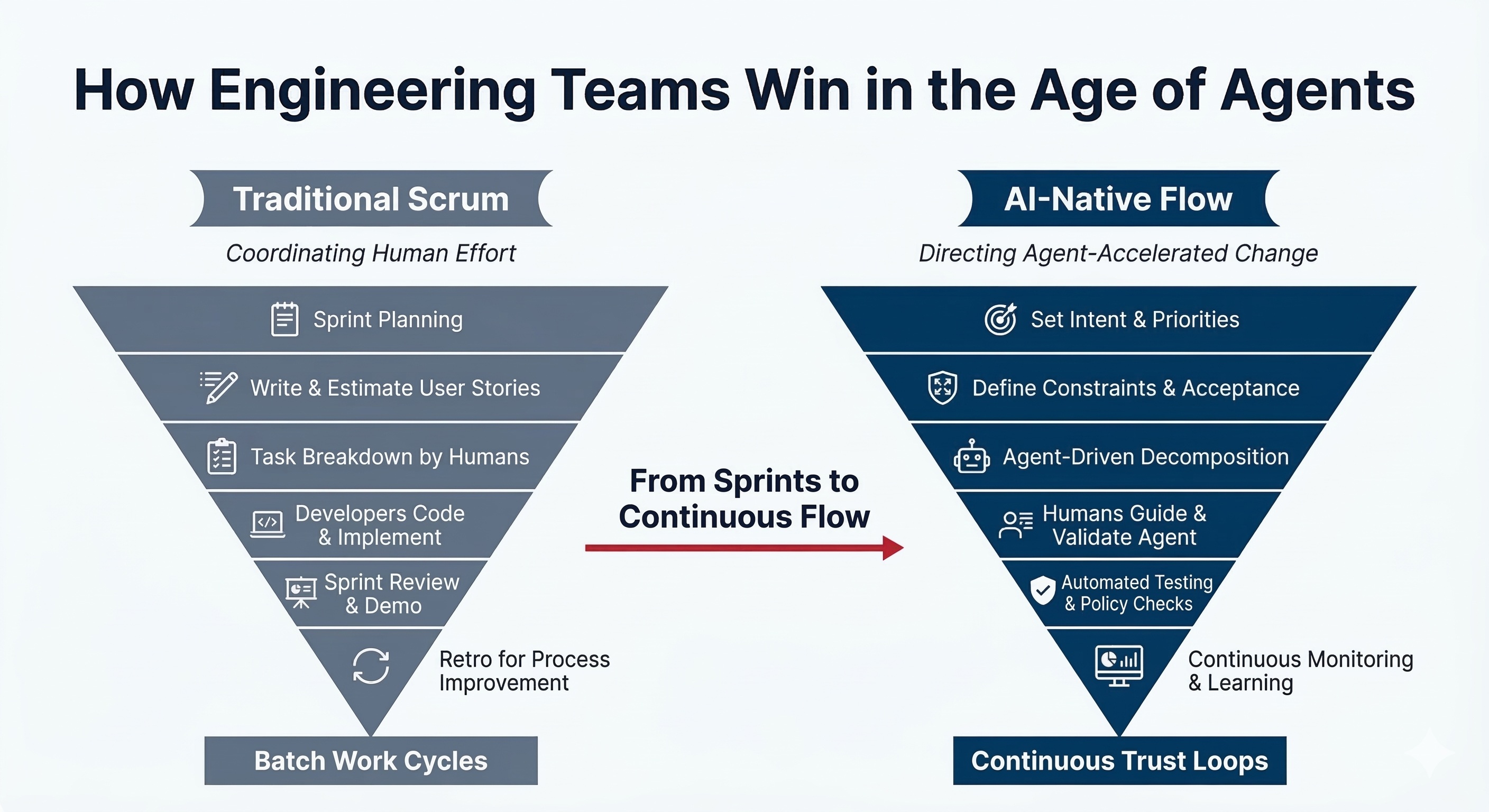
Sprints were built for a world where humans wrote the code
The Agile Manifesto was written in 2001. Two-week sprints, story points, daily standups, velocity tracking: these were rational answers to a specific problem.
The problem was that implementation is slow and expensive, so coordinate your human developers carefully. Batch your planning. Protect the execution window. Review and adjust every cycle.
That model made sense for 25 years. The core assumption was that human coding capacity was the scarcest resource. Build planning ceremonies around it. Optimize for it. Measure it.
Agents removed that assumption.
When an agent can read a ticket, decompose it, generate an implementation, write the tests, and raise a PR in the time it takes a developer to read the ticket and open their IDE, the two-week sprint stops being a rational unit of work. It becomes a ceremony optimized for a constraint that no longer exists.
The teams adding AI tools to their existing sprint workflow are not becoming AI-native. They are bolting a faster engine onto a chassis designed for a different era. Sprint planning is still asking: how much can our humans build this cycle? That is the wrong question. The right question is: how clearly can we specify what we want, and how safely can we verify what the agent produces?
Nobody is asking that in sprint planning.
Agents made execution cheap; they did not make judgment cheap
For most of the history of software development, judgment and execution were bundled in the same hire. Writing code was hard, so implementation speed was the proxy for engineering value.
Agents unbundled this.
Execution is now cheap. An agent generates code without complaining, without getting tired, without needing context explained across three planning sessions. It will produce an implementation of exactly what you asked for, whether or not what you asked for was the right thing to build.
That last part is the whole problem.
The new scarce resource is not implementation speed. It is the quality of direction: can you tell the agent the right thing to build? The quality of context: does the agent have what it needs to build it correctly in your specific system? And the quality of verification: can you trust what it produced enough to ship it safely?
These are judgment questions. They require a different kind of process than sprint ceremonies were designed for.
The teams that understand this have changed what engineers spend time on. Less implementation. More specification, architecture thinking, and verification. The bottleneck moved upward. The best teams moved with it.
The tool debate is the wrong conversation
There is a real and ongoing debate among engineering teams about which AI coding tool is best. Which assistant, which model, which IDE integration. Teams run evaluations, compare outputs, debate pricing.
This debate is mostly a distraction.
The tool is not the bottleneck. Teams I have worked with running the best AI tooling available produce inconsistent results, because they hand agents vague tickets and hope the output is usable. Teams I have seen with simpler setups ship reliably, because they invested in what agents actually need: clear architecture documentation, explicit domain rules, and tickets written as outcomes with acceptance conditions rather than implementation steps.
The agent performs to the quality of what you give it.
A well-specified ticket in a well-documented codebase with explicit guardrails produces far better output than a vague ticket in a legacy codebase, regardless of which tool you use. Switch tools and your context-poor codebase is still context-poor. Invest in the context layer and every tool you run on top of it improves.
The teams obsessing over tool selection are asking the wrong question. The right question is: what does our agent need to do its best work, and have we built that?
Context is the real source code
Software development has always been about managing the scarcest resource. In the early days, that was the ability to write working code at all. Then it shifted to managing complexity: architecture, abstractions, reliable systems. Then to speed and integration: ship fast, connect services, operate at scale.
We are in another shift. The scarcest resource now is context.
Context is everything the agent needs to generate trustworthy output: the architecture decisions it must respect, the domain language specific to your system, the constraints it cannot cross, the test intent that tells it what "working" actually means in your codebase. What used to live in senior engineers' heads must now be made explicit, written down, and available to the agent before it starts work.
In practical terms this means a CLAUDE.md or equivalent file that tells the agent what it is working in and what it must not touch. Architecture decision records that explain why the system is shaped the way it is. Domain glossaries. Explicit rules about testing patterns, security requirements, and deployment constraints. Tickets written as intent plus constraints plus acceptance conditions, not as implementation instructions.
Most codebases have none of this. Agents in those environments make confident decisions based on incomplete information. The output looks plausible and is often wrong in ways that take hours to debug.
This is why the same AI tool produces dramatically different results across teams. The teams investing in context are experiencing compounding returns. Every improvement to the context layer makes every future agent interaction better. The gap between them and teams running agents on context-poor codebases is widening, not narrowing.
The operating model that actually works
The best way to think about how AI-native teams operate is as three stacked responsibilities, not a linear pipeline.
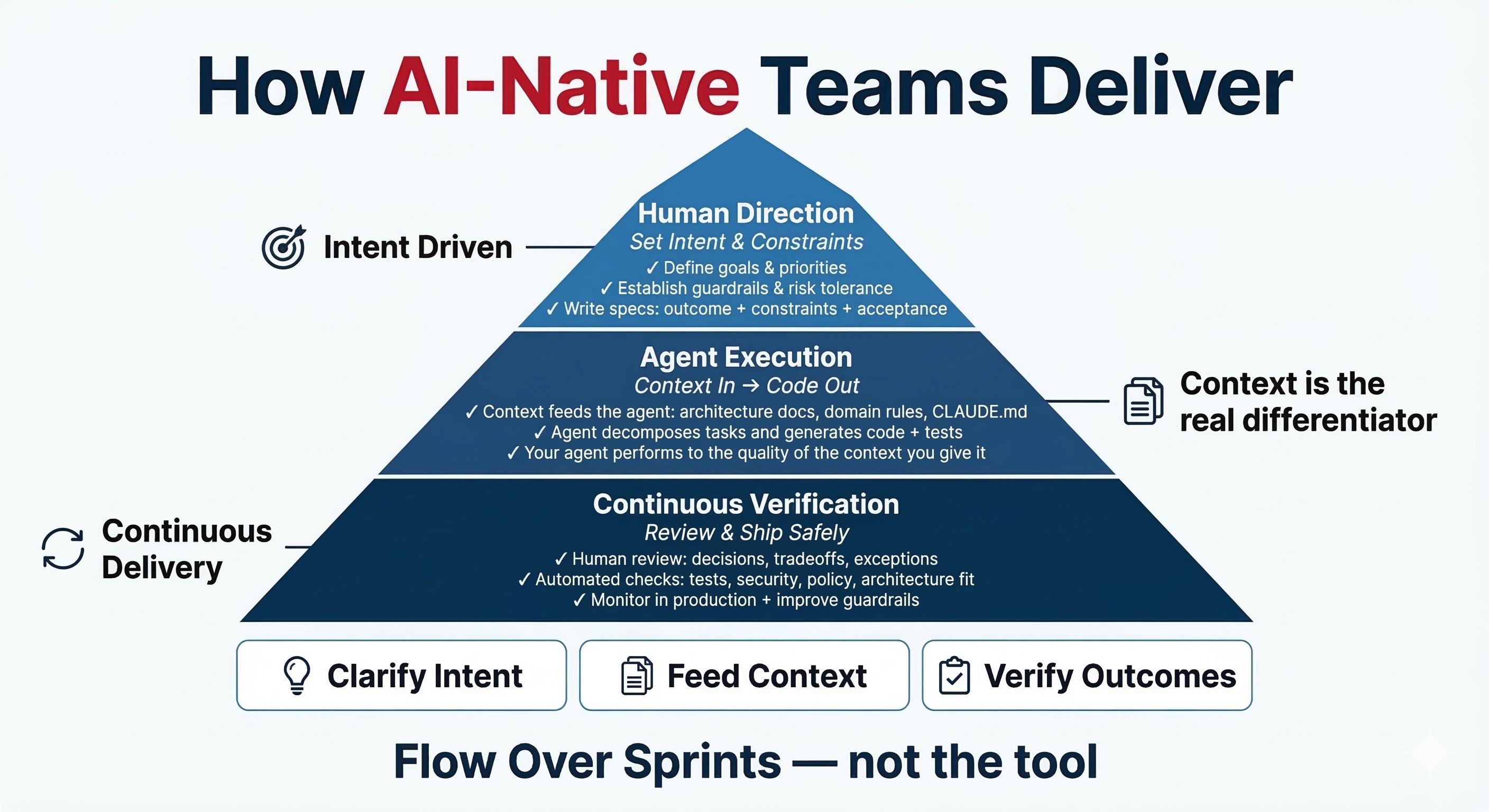
Human Direction sits at the top. Humans set intent, priorities, and constraints. This is not just writing a ticket. It is: what outcome are we driving toward? What are the guardrails? What must hold true for this to be done? What is the risk tolerance? This layer requires the architectural judgment and business context that agents cannot replicate, and it is the most leveraged work an engineer can do.
Agent Execution is the middle layer. Agents decompose, generate, and implement. This layer moves fast. The agent takes the specification and produces code, tests, documentation, and change preparation. The output quality is bounded by the specification quality. This is where most teams focus their attention. It is not where the bottleneck lives.
Continuous Verification is the foundation. Human review for decisions and tradeoffs. Automated checks for tests, security, policy, and architecture conformance. Observability in production. Feedback loops that improve the guardrails over time. This layer is the hardest to scale, and it is where the real bottleneck sits for most teams attempting AI-native delivery.
The teams making process investments in the execution layer, choosing better tools and faster agents, are optimizing the middle. The teams making investments in the verification layer, building the infrastructure that makes it fast and safe to trust agent output, are building the actual competitive advantage.
The board does not match the work anymore
The standard sprint or Kanban board has three columns: To Do, In Progress, Done. Sometimes with a code review column added. This reflects a world where humans implement work and other humans review it.
It does not reflect the actual flow of AI-native delivery.
The real flow is: the ticket needs to be specified clearly enough to hand to an agent. The agent generates a draft. A human reviews decisions and tradeoffs, not implementation line by line. Automated checks run. The change is verified safe to ship. It goes to production where the team monitors outcomes and learns what to improve.
The column most boards are missing is the gap between agent output and human review. That gap is where trust either exists or does not. Making it visible as an explicit stage is the first step to managing it. Teams I have worked with who added this column found their bottleneck immediately: humans were becoming the constraint again, not because implementation was slow, but because they were reviewing everything manually instead of building automated verification they could trust.
Estimation changes too. Story points built on implementation effort become unreliable when execution speed is variable and agent-driven. The more useful questions are: how risky is this change, how much is unknown, and how hard is it to verify safely? Those dimensions give reviewers better information than effort estimates ever did.
The three investments that compound
The teams pulling ahead are not the ones that moved fastest to adopt tools. They are the ones that made three investments before the adoption pressure arrived.
Codebase clarity. Architecture decision records, domain documentation, explicit rules about what can and cannot be changed and how. This is the raw material that makes agents reliable. Without it, agents make confident wrong decisions. With it, they generate changes that fit the system they are working in.
Specification quality. Engineers who know how to write a brief that an agent can act on: outcome, constraints, acceptance conditions, and risk level. This is a skill most teams have not deliberately developed. The teams that have treat ticket writing as the highest-leverage activity in the workflow, not admin.
Verification infrastructure. Tests that describe the intended behavior of the system, not just tests that pass. Security and policy checks in the pipeline. Observability that surfaces production problems early. The ability to say with confidence that a change is safe to ship, without a human reading every line.
These investments were valuable before agents arrived. Now they are the primary differentiator. Teams that made them are compounding. Teams that did not are discovering that agents generate mess faster in a messy codebase.
The process question worth asking is not "how do we add AI to our current workflow?" It is: what does AI-native delivery actually require, and how far are we from it?
Most teams have not answered that question seriously yet. The ones that have are the ones winning.
I help engineering teams close the gap between "we use AI tools" and "AI actually changed how we deliver." Book a 20-minute call and I'll tell you where the leverage is.
Working on something similar?
I work with founders and engineering leaders who want to close the gap between what their technology can do and what it's actually delivering.